Object detection model training¶
Deprecation notice
Detection model training is currently being refactored and will be updated soon. YOLO detection models trained with the previous approach are not supported anymore after insect-detect v2.0.0.
YOLO (You Only Look Once) (Redmon et al., 2016) is the first object detection model which combines object detection (bounding box prediction) and classification (associated class probabilities) into a single neural network. This new approach makes the model very fast and enables its use for real-time inference, even on resource-constrained hardware. After the first release, several new YOLO versions improved the initial model and formed the YOLO family.
Check out the provided Python scripts and the recommended processing pipeline for more information on how to deploy your custom trained detection model.
YOLOv5¶
YOLOv5n is the most recommended model for the DIY camera trap at the moment.
YOLOv5 (Jocher, 2020) is probably the most popular YOLO version, including models for object detection (architecture summary), image classification and instance segmentation.
It is highly recommended to read the tips for best training results if this is your first time training a detection model. Most of these tips are also relevant if you choose a different YOLO version.
-
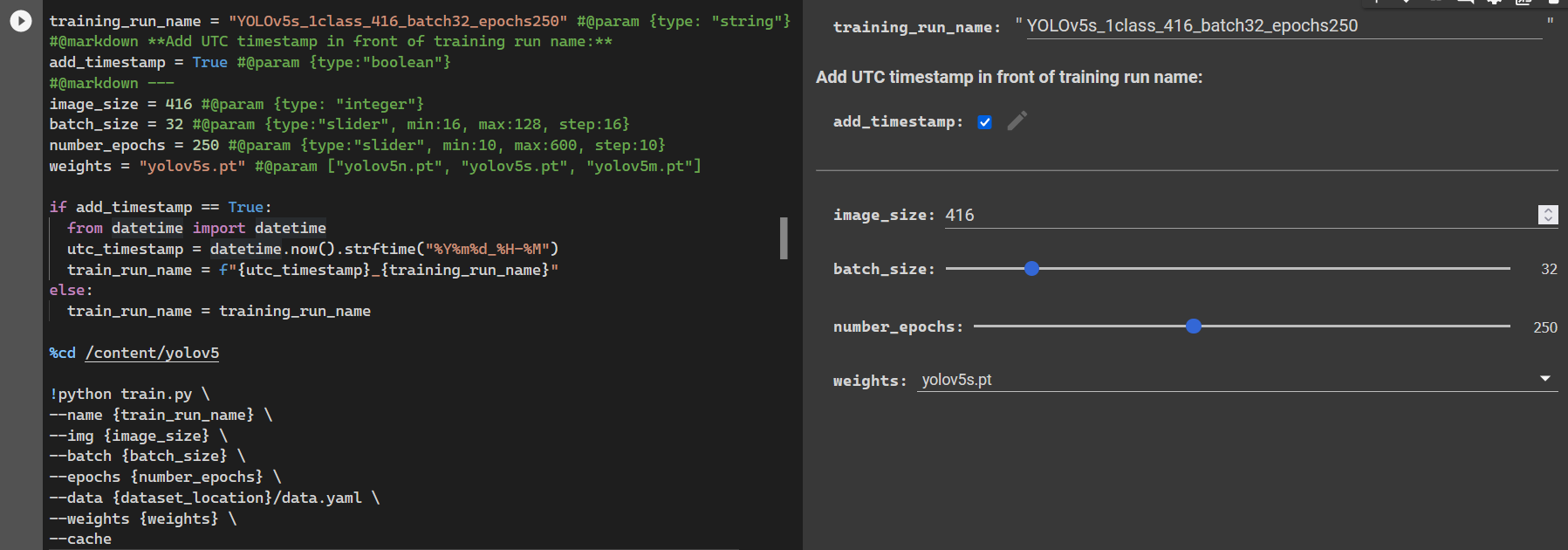
YOLOv5 detection model training

The PyTorch model weights can be converted to .blob format at tools.luxonis.com for on-device inference with the Luxonis OAK devices.
Check the introduction and features overview if this is your first time using a Colab notebook.
YOLOv6¶
YOLOv6 (Li et al., 2022) is specifically tailored for industrial applications and implements several new features, including a efficient decoupled head, anchor-free detection and optimized loss functions which can increase model performance.
-
YOLOv6 detection model training
The PyTorch model weights can be converted to .blob format at tools.luxonis.com for on-device inference with the Luxonis OAK devices.
YOLOv7¶
YOLOv7 (Wang et al., 2022) implements new features, e.g. Extended-ELAN (E-ELAN) to enhance the learning ability of the network, improved model scaling techniques and re-parameterized convolution which can further increase model performance.
-
YOLOv7 detection model training
The PyTorch model weights can be converted to .blob format at tools.luxonis.com for on-device inference with the Luxonis OAK devices.
YOLOv8¶
YOLOv8 by Ultralytics, the developers behind YOLOv5, claims to reach the current state-of-the-art performance by integrating new features, including anchor-free detection and a new backbone network and loss function. A big difference to other YOLO models are the developer-friendly options, such as the integrated command-line interface (CLI) and Python package.
-
YOLOv8 detection model training
The PyTorch model weights can be converted to .blob format at tools.luxonis.com for on-device inference with the Luxonis OAK devices.